Today, most of the web applications are Single Page Applications. In a nutshell, SPAs provide better customer experience where all the js, css, html are downloaded at one shot and based on the customer activity, screen gets updated dynamically. This approach provides enhanced user experience since the content loaded dynamically in the same page, page never gets reloaded and the user sees less of full white screen anymore. This is accomplished with the some of the modern client side javascript frameworks such AngularJs, ReactJs, Ember.js etc.
Since these frameworks have strong separation of concerns between View (presentation layer using html, js and css), Model (data that’s presented in the view using js) and Service (that fetches the data from the back-end using js), it gives us the advantage to test the presentation logic @ view level.
Stepping back to traditional applications, we didn’t have this separation as clear as its now, hence the test automation techniques had to stand out and test the whole GUI as a blackbox. Tools such as webdriver, QTP, Microsoft CodedUI etc help here, they have evolved over time and certainly paid of. But primarily they are targeted from outside in perspective, the adoption is never friction less.
Some common challenges that stand in the way towards true cross functional scrum teams
Blackbox – these technologies (webdriver, QTP etc) don’t play well with developer stack. Although webdriver has APIs in every possible language, still it’s not near and dear to the developer hearts. When they refactor the UI, leave test code behind and accumulate debt. Very common one and hard to overcome. I see this everyday.
- Cost of automation – related to the previous point, cost of maintenance seems high. Although the maintaining the test should be part of the story that caused the drift in the first place but practical acceptance of this is far from reality.
- Late feedback – everyone would love to get feedback as soon as the change is made part of the development process(in milliseconds). Blackbox testing requires the code to be checked in, built and deployed. Its not milliseconds for sure. You are lucky if its in minutes.
- Failure analysis – since these are end to end and from outside, failure cause could be anywhere in the stack and test failure report wouldn’t give you any of that insight.
- Confidence level – this is possibly the outcome of all the above and many more challenges. At the end of the day, developer wouldn’t feel the necessity of browser driven tests due to high cost low return factor.
In attempt to make Quality part of developer life, I wanted to resolve these issues as much as possible, offer as much as tooling and guidance to solve these challenges.
View testing came in handy to address some of these but certainly not all. Its not replacement of e-e GUI tests but certainly could lower the burden of GUI tests and improve the developer culture, morale and confidence in test automation.
In essence, here is the guidance
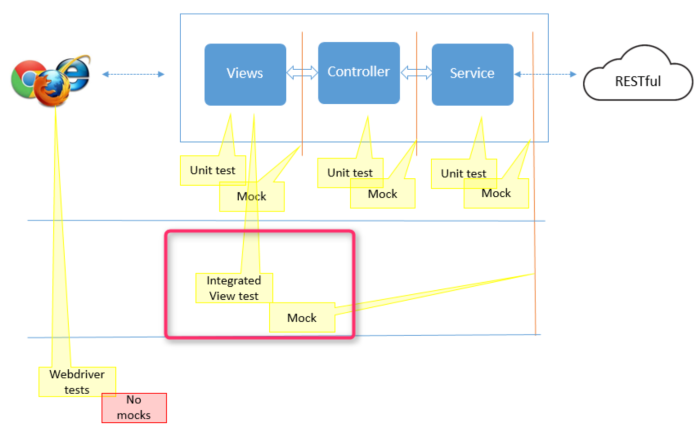
- View tests – tests discrete components/directives for adequate combinations of props and states – JS driven, early feedback, near and dear to developer heart, easy to maintain, gives us most of the confidence. Inch wide, mile depth.
- E-E GUI tests – tests multiple user journey, blackbox testing from outside – Webdriver driven, browser tests, late feedback, gives us the last mile confidence . Mile wide, inch depth
If this is something interesting, continue to read. I’m demonstrating this with a ReactJs based application.
This is a simple Login component written in ReactJs.
Some of the behaviors we want to verify
- should render username input box with placeholder ‘something@email.com’
- should render password input box as type=”password”
- should render remember password checkbox
- should render remember password unchecked by default
- should toggle remember password when clicked
- should allow the user to key in username
- should clear username when cancel clicked
- should clear password when cancel clicked
- should NOT render any notification onload
- should render “WIP” while attempting to login
- should render “WIP” while attempting to login
- should render “SUCCESS” upon successful login
- should render “SUCCESS” upon successful login
- should render “ERROR” when login fails
- should render “ERROR” when login fails
Behaviors 1 thru 4 can be verified as unit tests since they are mostly view specific.
Traditionally, behaviors 5 thru 15 were tested thru GUI tests because they needed real browser for events simulation such as clicks, enter user, password etc. So, our goal is to see how to we can use the view testing guidance to test these behaviors.
Technology
- Javascript – to create tests
- Mocha – as a test runner
- JsDOM – to mimic browser DOM in Nodejs
- ReactJs, Flux – as a framework for dynamic web app
Setup
Clone the source code from here and install dependencies (npm install)
Tests are executed by running “npm run test”, that runs mocha. Since we are trying to mimic browser events, our component needs to be rendered inside DOM for us to perform certain actions such as button clicks, assert if correct class added to a node in the DOM tree etc. jsdom helps us with this.
This option in mocha.opts (–require ./src/components/__tests__/setup/setup) will make sure jsdom is loaded, global window and document is available before test execution.
Write tests
Now that we have the the setup, ready to write tests
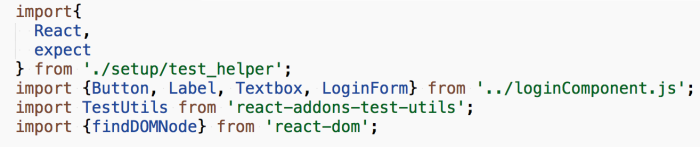
We need React, React TestUtils, our component and we could make use of react-dom apis to locate the elements in DOM tree.
React TestUtils will help render the component in jsdom. React-dom will help us to locate the elements from the DOM. React TestUtils got everything else to simulate events. Here is the list supported events.
Before running any test, we are going to render the document into the DOM using ReactTestUtils renderIntoDocument.

Now, react-dom provide nice wrappers around React to interact with DOM. We are using findDOMNode API to read values out of the DOM.
Here, I’ve defined all the locators in one place for easier maintenance and tests will ask for that element, element props and everything via this utility method getMe


With all the preparation done, ready to write tests. First 2 behaviors are written like this

In essence, we are asking for that element from DOM and asserting certain attributes. This is pretty straightforward and usual unit test testing technique.
Next one, is the real fruit. Mimic browser events.
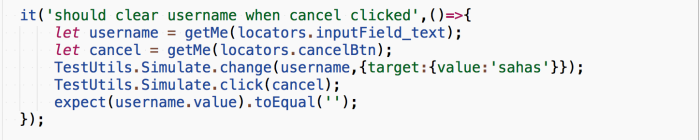
Here, in this test, we are asking for the elements form the DOM. Then using the Simulate api from React TestUtils to simulate the events.
Same way, we simulate actual login behavior as well. The fact here is we are not mocking the model or service.. when we simulate the login button click event goes thru the Flux architecture just like what would happen when user pushes the button on the app.
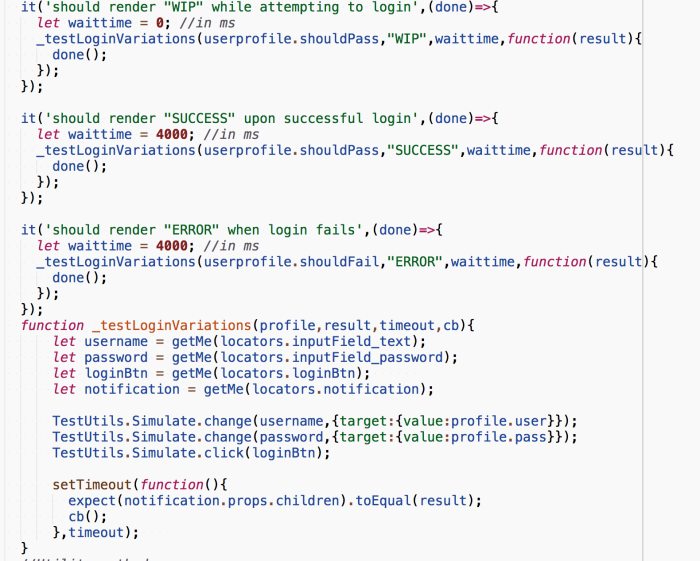
This is the speciality and value of this investment. we need not wait all the way to get the app deployed to verify these behaviors. In real world app, handling the timeouts could get get tricky but still manageable and maintainable. Feedback within seconds.
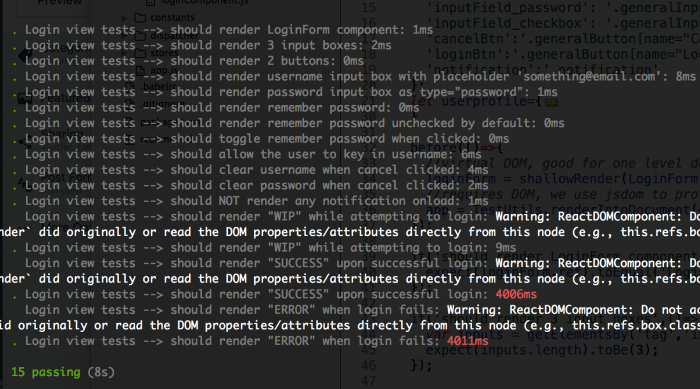
Certainly, this is not the alternate option for browser driven GUI tests, browser driven tests are needed to verify if the code still works on a given environment where we have greater influence of external factors and other integrating components. However, embracing view testing will help in verifying a component/directive in depth to elevate test automation stability, developer confidence, bring in more developer participation and let the team own quality.
What about Angular?
So, a lot of this is React. What if you use something else like AngularJs? there is browserTrigger, something similar to React Test Utils simulate api.